Requires one or more columns (samples), each containing counts of individuals of different taxa down the rows. In addition, one or more group columns with names of genera/families etc. (see below).
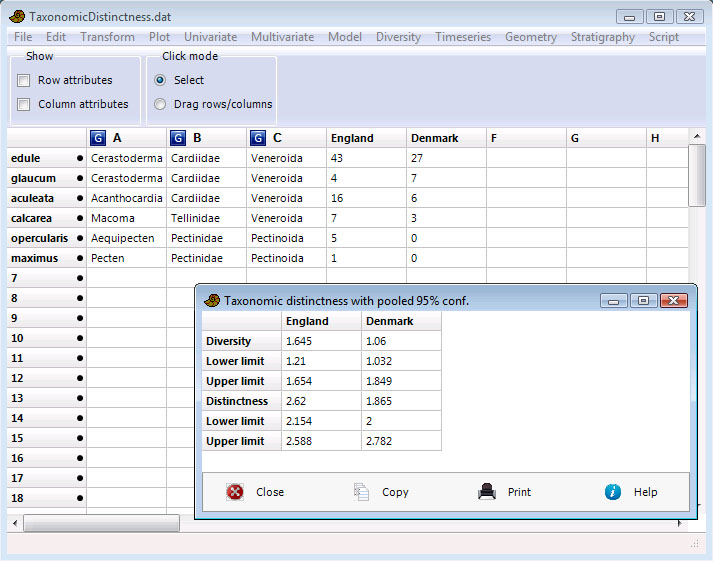
Taxonomic diversity and taxonomic distinctness are computed accordong to Clarke & Warwick (1998), including confidence intervals computed from 10,000 random replicates taken from the pooled data set (all samples). Note that the "global list" of Clarke & Warwick is not entered directly, but is calculated internally by pooling (summing) the given samples.
These indices depend on taxonomic information also above the species level, which has to be entered for each species as follows. Species names go in the name column (leftmost; in the Row attributes), genus names in the first group column, family in second group column etc., up to six group columns. Of course you can substitute for other taxonomic levels as long as they are in ascending order. Species counts for the samples follow in the columns thereafter.
For presence-absence data, taxonomic diversity and distinctness will be valid but equal to each other. For mathematical details, see the Past manual.
Reference
Clarke, K.R. & Warwick, R.M. 1998. A taxonomic distinctness index and its statistical properties. Journal of Applied Ecology 35:523-531.