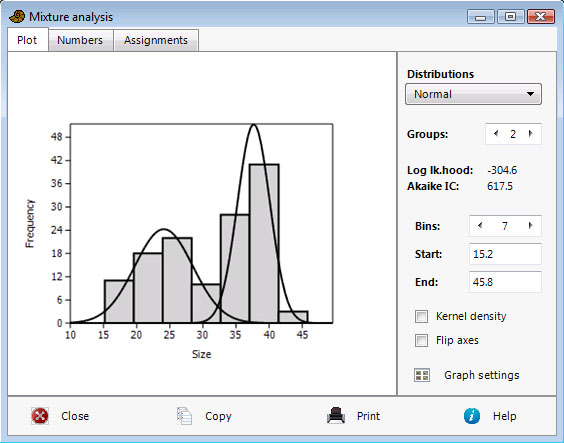
Mixture analysis is a maximum-likelihood method for estimating the parameters (mean, standard deviation and proportion) of two or more univariate normal distributions, based on a pooled sample. The program can also estimate mean and proportion of exponential, Poisson, and lognormal distributions. For example, the method can be used to study differences between sexes (two groups), or several species, or size classes, when no independent information about group membership is available.
The program expects one column of univariate data, assumed to be taken from a mixture of normally distributed populations (or exponential or Poisson).
PAST uses the EM algorithm (Dempster et al. 1977), which can get stuck on a local optimum. The procedure is therefore automatically run 20 times, each time with new, random starting positions for the means. The starting values for standard deviation are set to s/G, where s is the pooled standard deviation and G is the number of groups. The starting values for proportions are set to 1/G. The user is still recommended to run the program a few times to check for stability of the solution ("better" solutions have less negative log likelihood values).
The Akaike Information Criterion (AIC; Akaike 1974) is calculated with a small-sample correction. A minimal value for AIC indicates that you have chosen the number of groups that produces the best fit without overfitting.
It is possible to assign each of the data points to one of the groups with a maximum likelihood approach. This can be used as a non-hierarchical clustering method for univariate data. The “Assignments” button will open a window where the value of each probability density function is given for each data point. The data point can be assigned to the group that shows the largest value.
References
Akaike, H. 1974. A new look at the statistical model identification. IEEE Transactions on Automatic Control 19:716-723.
Dempster, A.P., Laird, N.M. & Rubin, D.B. 1977. Maximum likelihood from incomplete data via the EM algorithm. Journal of the Royal Statistical Society, Series B 39:1-38.